This is a repository that aims to provide a collection of badges to symbolize that you didn’t use generative AI (notably LLMs) for the creation of your project. By using this, you are expected to ensure that AI-generated code makes up less than 1% of the total written lines of code in your project. You can use the badge only if you ask for assistance like a smart grepper.
Note that nobody will check your code, and if you are against AI use in your codebase but are unsure about the number of lines of code written by AI, you can still use the badge. The goal is to be transparent and to try to reduce the abusive use of AI in codebases.
This repository is accompanied by an explanation that tries to be backed by scientific research to support every claim. But this part is still a work in progress.
What is the ‘by-human’ expected use of AI ?
AI should not be used in the project to generate code. It can instead be used as:
- A smart grep or a smart google. For example, fetching in a new codebase where something is implemented or maintained.
- Reviewer helper. When having a lot of PRs having an AI to catch bug.
- Learn a codebase (example: how do you do X ?) to learn by example or to explain something if there is no documentation. You should write the documentation after if you are maintaining the project.
- Using AI to ask for help with a bug, but not to write the fix for yourself.
- Asking how a feature could be implemented, but not to write the final implementation for yourself.
Every time you use an AI to help you think, it must be reviewed by a Human. You must also take responsibility of the elements the AI generated or told you.
Note that AI should be used sparingly and only after a Human was unable to provide a quick solution/alternative. You should always take into consideration the output of the AI and the consumption of energy & ecological footprint before using it.
Badge usage
You can copy paste code to your repository or directly use the logos in your project.
## Made by human
<a href="https://github.com/Supercip971/by-human">
<picture>
<source media="(prefers-color-scheme: dark)" srcset="https://raw.githubusercontent.com/Supercip971/by-human/main/transparent-light.svg">
<source media="(prefers-color-scheme: light)" srcset="https://raw.githubusercontent.com/Supercip971/by-human/main/transparent-dark.svg">
<img height="96" align="right" alt="Made by humand, not by gen AI badge" src="https://raw.githubusercontent.com/Supercip971/by-human/main/transparent-light.svg">
</picture>
</a>
[Project name] is made by **Humans**, and not by a generative AI.
More information can be linked to the [by-human](https://github.com/Supercip971/by-human) repository.
Made by human

[Project name] is made by Humans, and not by a generative AI.
More information can be linked to the by-human repository.
Raw badges
| Name | Picture (Dark) | Picture (Light) |
| transparent-dark.svg + transparent-light.svg |

|
|
| transparent-slim-dark.svg + transparent-slim-light.svg |

|

|
| filled-dark.svg + filled-light.svg |

|

|
| filled-slim-dark.svg + filled-slim-light.svg |

|

|
Why do we think writing using generative AI is problematic?
Writing using generative AI is inferior in multiple ways. It may appear better and more efficient, but comes with important drawbacks that we enumerate here.
1. Copyright, plagiarism and license-washing
1.1 Plain and obvious license-washing
AI can license-wash unknowingly, and it has already been shown that it can be used to do it on purpose [1].
TL;DR: Claude Code was used to ‘rewrite’ an entire project, which was then relicensed under the MIT instead of the LGPL.
This is a clear license violation.
If one were to claim that it was not, then would tanslating a book remove its copyright? Accepting such a claim would effectively mark the end of copyleft and copyright protections.
1.2 Plagiarism, and not obvious license-washing
When making an LLM learn, it is unable to grasp the license of the code. As shown in two research papers, [2] [3] Large Language Models are generating 3.35% of strong copyleft licensed code and are:
not aware of reusing copyleft code and cannot be asked, through the prompt, to avoid reusing existing code in the responses.
This paper [2] also states that accepting a copyleft request may lead to an increase in copyleft stolen code. (By a factor of 2 to 5).
Ultimately, LLMs are blatantly plagiarizing code. It is a far cry from a human learning about a chunk of code and then creating something based on obtained knowledge; a human fundamentally understands the whole picture and the idea behind the code, and does not rely on rote memorization.
But when an LLM learns, it takes in a large quantity of code from a variety of sources and may spit it back out verbatim to oblivious users. Meaning that the strongly licensed part of the code is in its database, raising concerns about the respect of license.
This is different from a human importing a licensed piece of code, as a well-informed developer will include the license notice along with the chunk of code. In lieu LLMs don’t mention the license nor the author.
2. Creation of bugs
We will first let the numbers speak for themselves:
- [4] Is stating that Chat-GPT 4 is instantly failing ~8% of the time, and code quality is good only ~60% of the time.
- [5] code rabbit, an AI company, announces that LLMs introduce 70% major defect and 40% critical issues in pull request. Twice more than humans.
- [6] this paper notify that Github-copilot has only superficial capabilities when trying to find bugs. It can hardly help discover bugs. Across multiple projects filled with vulnerability issues (more than 39 different types), GitHub Copilot only assisted in finding a couple, but in general it only fixed spelling mistakes. Finally, GitHub Copilot lacked any valuable comments
- [7] Uplevel reports that generative AI is introducing 40% more bugs.
- [8] puts into perspective the fact that we have a year over year increase of 40% of code pushed, then reverted or removed within 2 weeks. Meaning that since the introduction of AI, quickly ‘reverted’ code has increased from 3.97% to 7.09%.
Inexorably, we understand that AI generates incremental technical debt, that makes projects unmaintainable in the long term. And it’s barely able to fix itself.
It’s like a student writing code for you and not being able to learn and have cognitive introspection. And you, the programmer, are less likely to fully understand your code as you did not write it.
2.1 You seem smarter, but you are becoming worse
- In some research[9], it is shown that using AI makes you 48% to 127% more likely to achieve a better grade during practice problems. But in the end, you are 17% more likely to achieve a worse grade during the real test.
What is worse, is that those students were not able to realize that they learned less. And were unable to become more understanding.
This is a critical issue because you are leading to a false sense of knowledge. Generally you write code using AI and trust your competence by checking it. But you are becoming a really bad programmer by trusting the AI and not learning by yourself.
As you are expected to study your codebase, by using an LLMs, you are becoming worse at understanding your own codebase, thus worse at fixing and improving it.
Ultimately, this makes you more and more dependent on AI, and this will turn into a vicious cycle until your codebase is unable to be maintained.
3. Is the ecological aspect devastating?
It is rough to translate into numbers the ecological aspect of AI.
First, 70%[10] of ram production is dedicated to datacenters. A production increased by the reallocation of supplier capacity towards AI datacenters. Meaning that we are using a lot of economic resources to make AI run.
[11] Since the introduction of chat-GPT, the power consumption has elevated by 98% in one year. (2.69 MW in 2022 -> 5.43 MW in 2023).
The water usage is hard to put into perspective. The only trustable source is a citation from Sam Altman saying that Chat-GPT uses 0.000085 gallons of water per query. [12] but Chat-GPT processes 2.5 billion of request per day [13] meaning that on average Chat-GPT uses 804,400 L of water per day.
Thenceforward, this article tells us that [14] one Chat-GPT 4.5 request costs 20.500 Wh. But you can still not make this statement as clear as possible, as it uses an approximation.
It is more grounded as this article takes into account large context, because a lot of studies use ‘short’ requests. Although using an LLM as an agent requires it to read your file, your codebase, and can no longer be linked to a ‘short request’.
While it may seem a lot, those numbers are a ghost. We can’t make any further claim and are not able to put into perspective the direct ecological aspect of Chat-GPT usage. We would need a full research that is using OpenAI insights. On the other hand, as they are not releasing a lot of information we are stuck at guessing how much we are collapsing the world by using AI.
4. LLMs are getting better!
4.1 Inbreeding is as bad as it is for humans
Microsoft is training its LLMs on code from github, and they expressed in a conference that 40% of code written by an LLM is left unmodified [15].
Although this quote is not really backed by any evidence, it is admitted to be true that more and more published code is written by an LLM, and it is progressively left untouched.
The training data of LLMs can’t differ between a human code and a LLM written code. Hinting that we will need more and more energy, training and data to accommodate this shift in quality.
An error just repeated multiple times by an LLM can become ground truth. It has been shown that only 20 documents can poison LLMs of any size [16]. (While this is not directly linked to this statement, this article shows how a couple of documents can shift an LLM’s point of view).
In summary, the easy shift in model knowledge coupled to the booming use of LLMs in the wild means that LLMs are now training on their own data, leading to a considerable decrease in training quality.
It’s just like inbreeding.
4.2 Compute power availability
Having to pay twice for your ram is a heavy cost of having datacenter eating the whole production.
AI is mainly able to evolve by multiplying compute power, RAM, context size… Yet our world is unable to keep up with it [17].
This paper crystallizes the concern with this statement:
Empirically, Sutton’s “bitter lesson” (Sutton, 2019) appears partly incorrect: it is not that, for AI, “general methods that leverage computation are ultimately the most effective, [because of] Moore’s law, […] continued exponentially falling cost per unit of computation”, but that increasing resources are spent on AI. This increase in resources is visible in computational costs but is also true of other costs. For instance, building larger AI models require more human labor. [17]
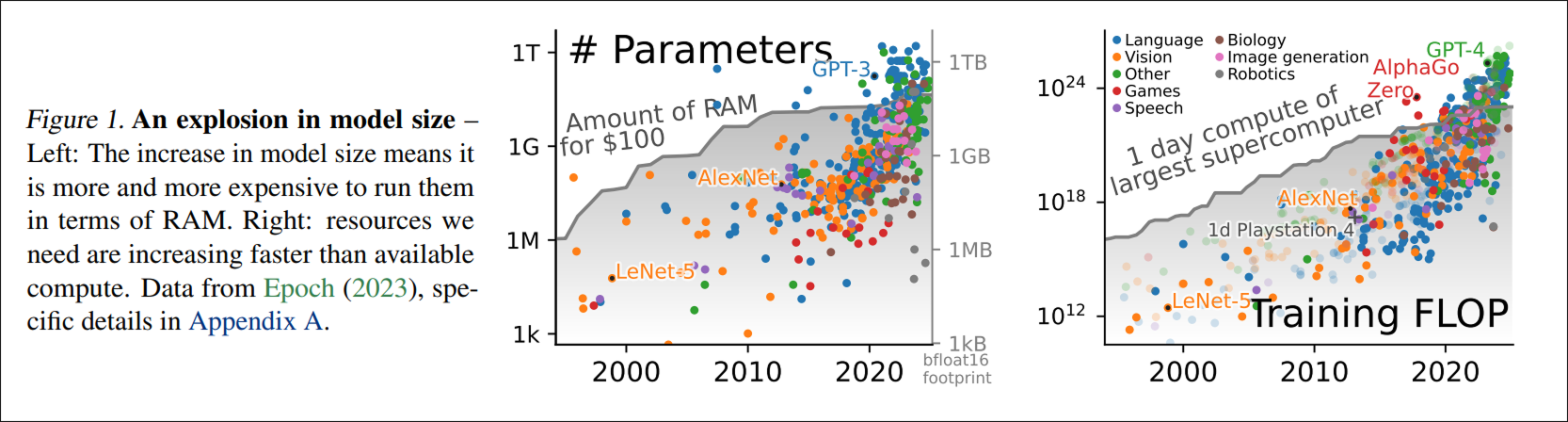
Subsequently, when we say an AI is getting better, it is not because of a ground breaking algorithm but rather:
- More powerful hardware, which takes more money and consumes more energy
- More data (which is becoming more and more polluted by LLMs)
- More training, meaning more energy and more human labor.
We are reaching a point where we are sidelined to keep up with the increasing demand of resources, and the only way to keep up is to eat through the user market. The paper may have predicted the increase of recent ram price [18].
When we will no longer have enough ram, no longer enough compute power, the whole AI industry may collapse, bringing us back to the point where we are now… And those who depended on AI will not be able to bring back their lost knowledge.
If you want to be positive, it may quickstart a thought of reversing computer evolution. And trying to become more efficient rather than more performant.
Conclusion
When writing code using AI, the process can seem almost like magic, because the problem may have already been solved by someone else and reproduced by the model.
It makes you look smarter but simultaneously makes you worse at solving problems on your own. AI is destroying the planet and our economy while getting worse, polluting its own data set. The situation is only worsening as investors are contributing billions, expecting more and more, while getting less and less in return.
It is only a temporary shiny rock that will become just a crusted rock. And hereafter, you would have hoped to not depend your whole workflow on an inbred junior that is unable to count the number of letters in a word. You will finish as the external tourist of your own codebase.
The world is made of complex problem and there are no easy fixes. Our imperfection and thought process may be replicated someday, but for now your brain is precious.
Programming has yet to be solved, and we are building our own babel tower trying to reach AGI while destroying our knowledge with bricks of ourselves.
Please learn, discover, and make something creative.
Shouldn’t I use brainmade.org ?
We don’t share the exact same philosophy as brainmade.org, they say:
It’s not AI = bad, it’s human = good.
There’s something transcendent and magical in knowing a human made the artwork I’m consuming, knowing they tried hard is part of the experience.
It doesn’t have to be 100% human made (what would that even MEAN these days?), perhaps 90% human made.
Three examples of what this mark could apply to:
- Using, say, ChatGPT as a rhyming dictionary feels fine, but writing whole verses of your poem doesn’t.
- Using DALL-E to start brainstorming with 100 generated views of birds sitting on telephone lines seems fine, but getting it to paint large sections of your artwork doesn’t.
- Asking a text generator to give you 10 happy-sounding synonyms for despair sparks joy in me, but asking it to write your anti-transcendentalist masterpiece does not.
And that’s okay, for some people they see AI is a tool and can be used sometime. And for us, it is not a tool for writing but rather a poison that can lead to knowledge debt. It should be used sparingly at all costs. And avoid using it to write code.
Sources